作ったもの
環境
開発環境は以下の通りです。
| 名前 | バージョン |
|---|---|
| Deno | 2.5.6 |
| TypeScript | 5.9.2 |
| Fresh | 2.2.0 |
| Tesseract(npm) | 6.0.1 |
画面キャプチャからOCR実行までの流れ
画面ストリームの取得と表示
画面キャプチャAPIを用いて、ユーザーに共有する画面を選択してもらいます。
const mediaStream = await navigator.mediaDevices.getDisplayMedia({
video: true,
audio: false
});ここで取得したMediaStreamをuseStateで<video>タグに割り当て、表示します。
この映像が、今回OCR処理をする元データとなります。
静止画の切り出し
OCR処理をするために、静止画を切り出します。
はじめに<video>タグからフレームを切り出し、<canvas>に書き出します。その後Base64形式の画像データにします。
const captureFrame = ()=>{
const ctx = canvas.getContext('2d');
ctx.drawImage(video, 0, 0, canvas.width, canvas.height);
return canvas.toDataURL('image/png');
};OCRの実行
ここでTesseractを使用するのですが、npmの依存の関係(?)でファイル先頭に
import Tesseract from 'tesseract'とするとエラーが出たので、以下のようにしました。
const Tesseract = (await import('tesseract')).default;書き出した画像に対して処理を実行していきます。
const imageURL = captureFrame();
const result = await Tesseract.recognize(
imageURL,
'jpn'
);ここまでが大まかな流れになります。
実行してみる
Screen Capture APIのページを写して、OCRの実行をしました。
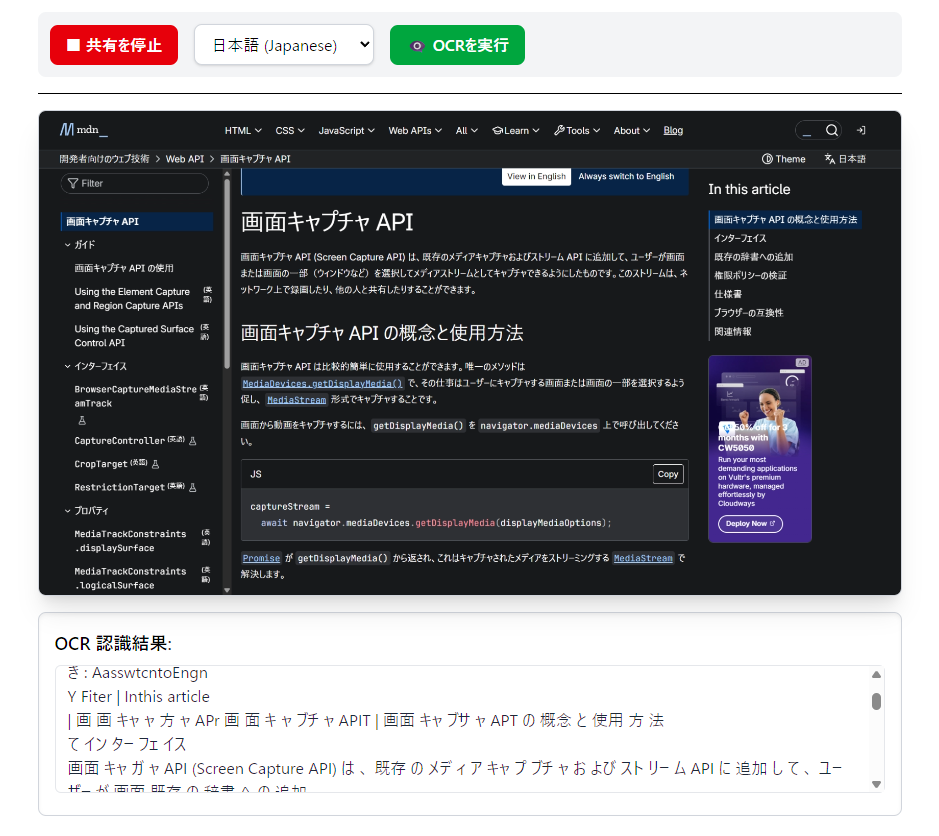
実行結果からもみてとれるように、精度は悪いですね...
まとめ
今回の開発では画像をサーバーに転送せず、ブラウザ完結型の画面OCRアプリケーションのプロトタイプ開発について紹介しました。ここでは特に画像の前処理などもしていなかったので、実行結果についてはいまいちだったのでここを改善していきたいと思っています。 また、翻訳機能を追加し、ゲーム画面や画像などをリアルタイムに翻訳できるアプリケーションを目指していきたいです。